Tatsuya Abe
Tatsuya Abe 
はじめに
弊社では 2025/5 から、Web アプリケーションを対象としたペンテスト (侵入テスト) を全自動で実行する AI Agent の研究開発を進めています。2026/1 には初回のフィールドテストを実施し、実環境でも脆弱性を見つけられることを確認しました。
弊社が研究開発しているのは、許可を得た環境に限定して脆弱性を検証し、サービス提供者の防御改善につなげるための技術です。悪用や無断での第三者システムへの攻撃を目的とするものではありません。
弊社のペンテスト AI Agent は、Web アプリケーションのブラックボックス / グレーボックステストを対象としています。現時点の入力と実行範囲は以下の通りです。
| 項目 | 内容 |
|---|---|
| 入力 | ターゲット URL。グレーボックステストでは ID/Pass も与える |
| 実行範囲 | 初期偵察、脆弱性の確認、レポート作成 |
| 出力 | 脆弱性レポート |
| 対象外 | 脆弱性レポートを自動提出する Bot、汎用的なインターネットクローラー、ホワイトボックステスト、ネットワークレベルのスキャナ |
本記事ではベンチマークでの基礎性能評価、初回フィールドテストの結果、主要な設計判断を紹介します。
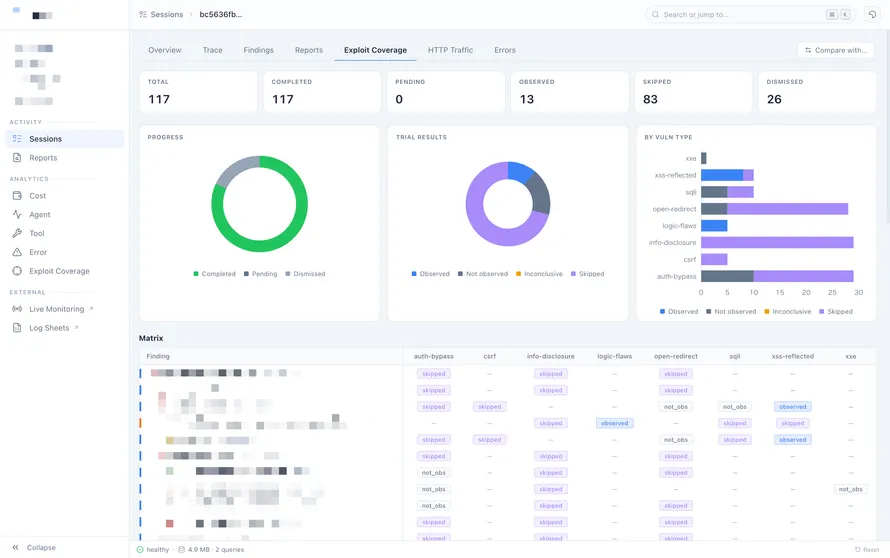
PortSwigger Academy Lab での基礎性能評価
PortSwigger Web Security Academy は、Burp Suite の開発元である PortSwigger 社が公開している無料の Web セキュリティ学習プラットフォームです。SQLi / XSS / SSRF など典型的な脆弱性カテゴリごとに攻略対象のラボ環境が用意されており、AI Agent / 人間問わず Web ペンテストの能力を測る共通の物差しとして広く参照されています。
開発初期は PortSwigger Academy Lab を使い、探索、攻撃、再現確認といった基本動作の改善を進めました。1 ラボあたり 1 時間の制限時間で実行したところ、2025/12/2 時点で 84% のラボを攻略できました。
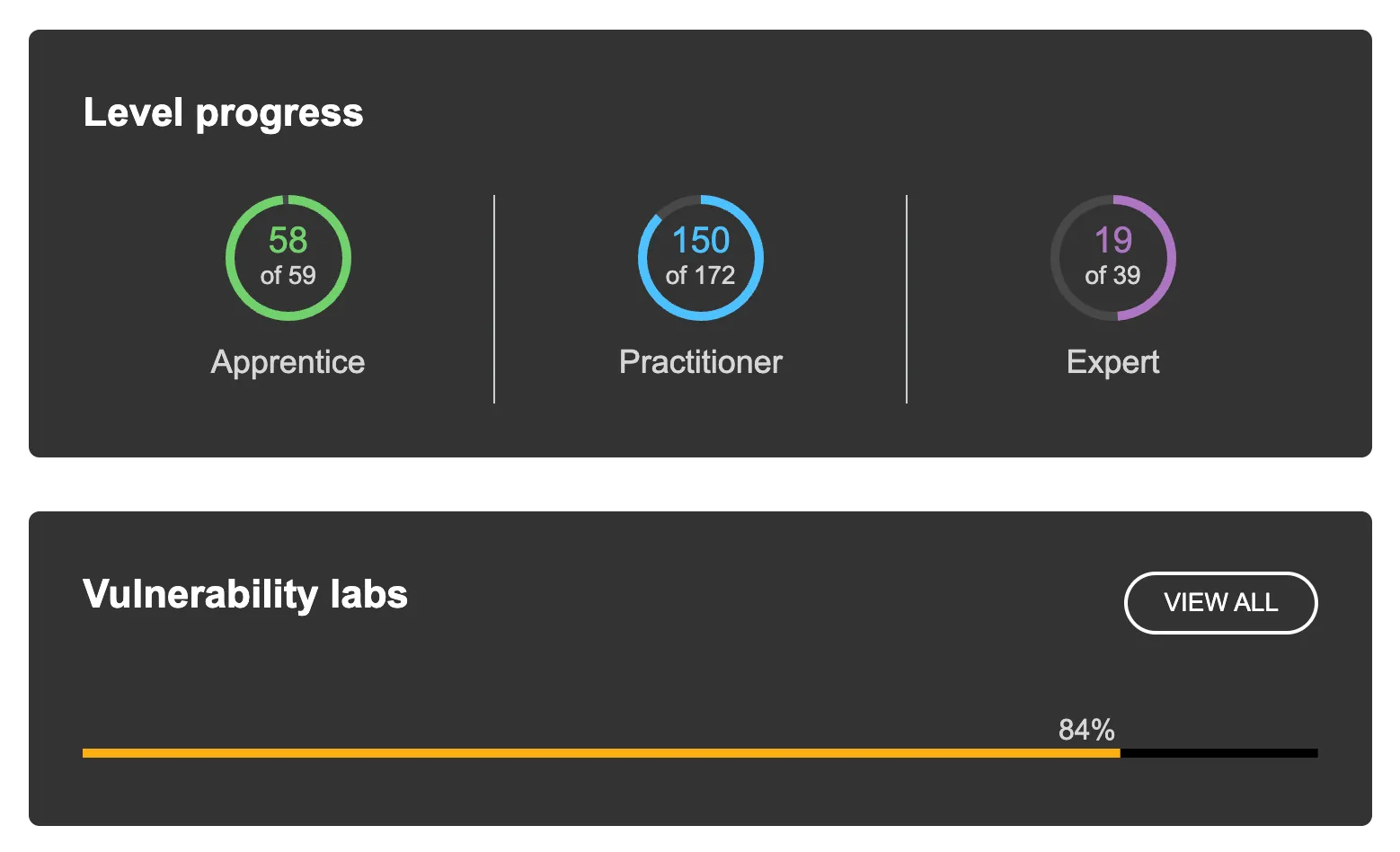
この結果を受け、既知の学習用環境だけでなく実環境でも脆弱性を見つけられるかを確認する段階に入ったと判断しました。
初回フィールドテストの成果
初回フィールドテストでは公開プログラムと協力企業のステージング環境の 2 系統で検証しました。
| チャネル | 対象 | 入力 | 目的 |
|---|---|---|---|
| HackerOne | 公開されている VDP / BBP | URL のみ | ブラックボックスでの実環境検証 |
| 無償 PoC | 協力企業 1 社のステージング環境 | URL と ID/Pass | グレーボックスでの実環境検証 |
HackerOne
HackerOne は、企業や政府機関が運営する脆弱性報告プログラムをまとめたバグバウンティプラットフォームです。プログラムは大きく 2 種類あります。
- VDP (Vulnerability Disclosure Program): 原則として報奨金は支払われず、責任ある開示の窓口として運営されるプログラム。政府機関のプログラムも多く含まれる。
- BBP (Bug Bounty Program): 妥当な脆弱性報告に対して報奨金が支払われる商用プログラム。
VDP / BBP 合わせて 30 件のターゲット URL に対し、URL のみを入力として 1 ターゲットあたり 1 時間のブラックボックステストを実行しました。
| 区分 | 結果 |
|---|---|
| VDP | 米国国防総省 (DoD) のプログラムで 3 件の脆弱性レポートが トリアージ (= 報告先の組織側で正当な脆弱性として認定) された |
| VDP リーダーボード | 90 days 部門で世界 86 位 |
| BBP | 3 件のレポートを提出 (いずれも先行報告ありで報奨金対象にはならず) |
この結果を受け、現在は HackerOne による実証実験を一区切りとし、後述する独自ベンチマークを使ったチューニングに注力しています。
無償 PoC
協力企業 1 社のステージング環境でも全自動ペンテストの無償 PoC を実施しました。入力は URL と ID/Pass のみでしたが、Stored XSS を含む複数の悪用可能な脆弱性を発見しました。
なお、対象システムや脆弱性の詳細は守秘義務および悪用防止の観点から非公開とします。
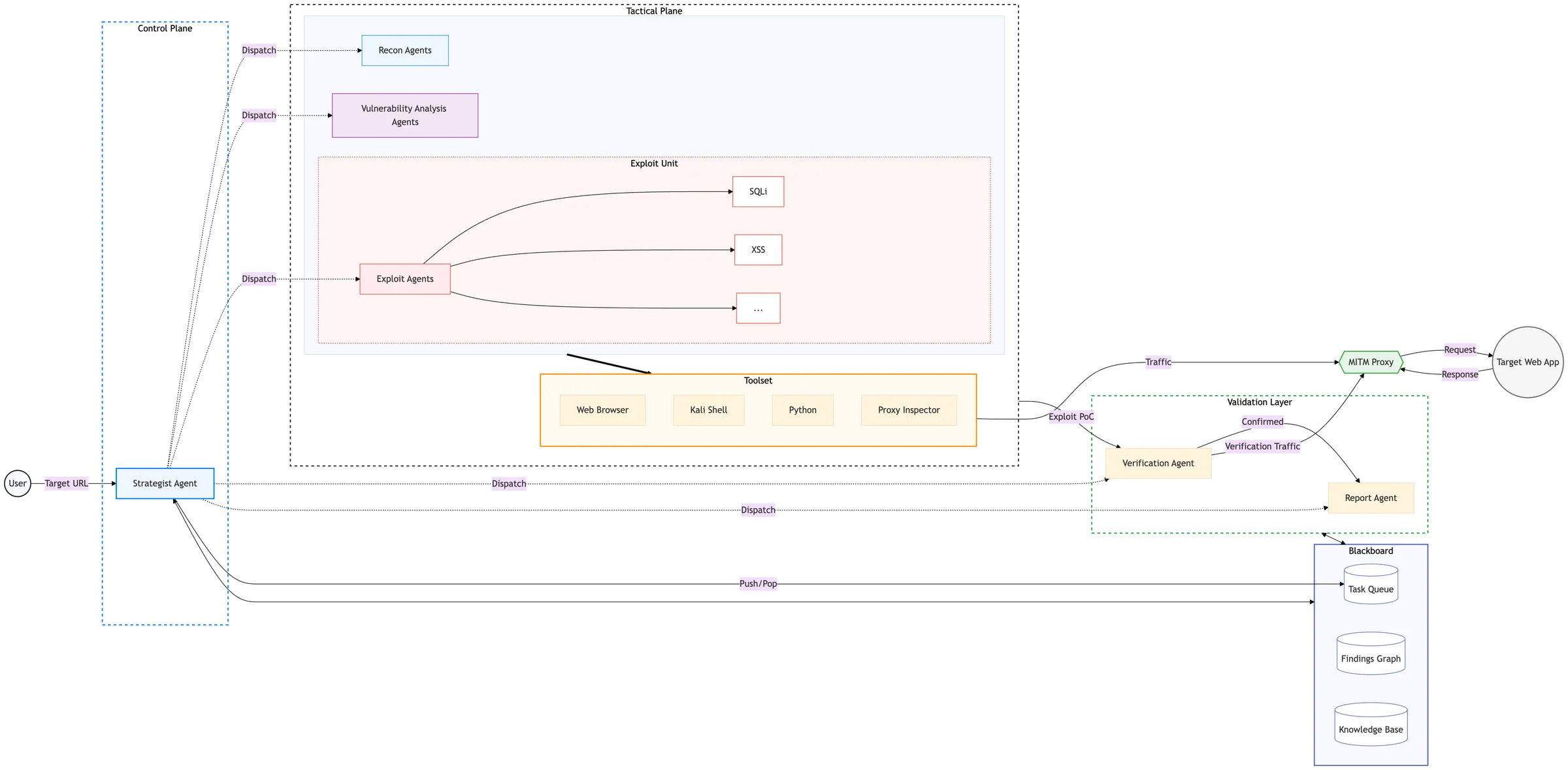
アーキテクチャと設計判断
ペンテスト AI Agent を全自動で動かす上で、設計上の悩みどころは大きく 2 つありました。
- 偵察、脆弱性探索、Exploit、再現確認で異なる要求をどう扱うか
- 人間の監督なしで動かす際に、スコープ外アクセスや過剰なリクエストをどう防ぐか
この前提で採用した現在の構成は以下の通りです。独自ノウハウに該当する部分は伏せ、公開可能な範囲に絞って説明します。
---
config:
layout: dagre
theme: base
---
flowchart LR
%% Entry Point
U(("User")) -- Target URL --> SA
%% Control Plane
subgraph Control_Plane["Control Plane"]
SA["Strategist Agent"]
end
%% Core Components
subgraph Blackboard["Blackboard"]
direction LR
TQ[("Task Queue")]
FG[("Findings Graph")]
HT[("Knowledge Base")]
end
%% Tactical Plane
subgraph Tactical["Tactical Plane"]
direction LR
subgraph Agents[" "]
direction LR
R["Recon Agents"]
V["Vulnerability Analysis Agents"]
subgraph E_Unit["Exploit Unit"]
direction TB
E["Exploit Agents"]
E --> SQLI["SQLi"]
E --> XSS["XSS"]
E --> ETC["..."]
end
end
Agents ==> Toolset
subgraph Toolset["Toolset"]
direction TB
BW["Web Browser"]
SH["Kali Shell"]
PY["Python"]
PI["Proxy Inspector"]
end
end
%% Validation Layer
subgraph Validation["Validation Layer"]
direction TB
VA["Verification Agent"]
RA["Report Agent"]
end
%% Infrastructure
P_Svc{{"MITM Proxy"}}
TWA(("Target Web App"))
%% Logic Flow
SA <--> Blackboard
SA -. "Dispatch" .-> R & V & E & VA & RA
SA -- "Push/Pop" --> TQ
%% Output & Verification Flow
Tactical -- Exploit PoC --> VA
VA -- Confirmed --> RA
Validation <--> Blackboard
%% Traffic Flow
Toolset -- Traffic --> P_Svc
VA -- Verification Traffic --> P_Svc
P_Svc -- Request --> TWA
TWA -- Response --> P_Svc
%% Style Definitions
style U fill:#f8f9fa, stroke:#212529, stroke-width:2px
style SA fill:#eef6ff, stroke:#007bff, stroke-width:2px
style Control_Plane fill:#ffffff, stroke:#007bff, stroke-width:2px, stroke-dasharray: 5 5
style Blackboard fill:#f8f9ff, stroke:#5c6bc0, stroke-width:2px
style TQ fill:#ffffff, stroke:#5c6bc0, stroke-width:1px
style FG fill:#ffffff, stroke:#5c6bc0, stroke-width:1px
style HT fill:#ffffff, stroke:#5c6bc0, stroke-width:1px
style Tactical fill:#ffffff, stroke:#333333, stroke-width:2px, stroke-dasharray: 5 5
style R fill:#f0f7ff, stroke:#2196f3, stroke-width:1px
style V fill:#f3e5f5, stroke:#9c27b0, stroke-width:1px
style E_Unit fill:#fff5f5, stroke:#f44336, stroke-width:1px, stroke-dasharray: 2 2
style E fill:#ffebee, stroke:#f44336, stroke-width:1px
style SQLI fill:#ffffff, stroke:#f44336, stroke-width:1px
style XSS fill:#ffffff, stroke:#f44336, stroke-width:1px
style ETC fill:#ffffff, stroke:#f44336, stroke-width:1px
style Toolset fill:#fffaf0, stroke:#fb8c00, stroke-width:2px
style P_Svc fill:#e8f5e9, stroke:#4caf50, stroke-width:2px
style TWA fill:#f5f5f5, stroke:#757575, stroke-width:2px
style Validation fill:#ffffff, stroke:#28a745, stroke-width:2px, stroke-dasharray: 5 5図中の Recon / Vulnerability Analysis / Exploit は単一の Agent ではなく、役割ごとに分かれた Agent 群を表しています。処理は大きく以下の流れで進みます。
| ステップ | 主な担当 | 内容 |
|---|---|---|
| 1. 戦略策定 | Strategist Agent | 共有状態を見ながら、次に実行すべきタスクを決める |
| 2. タスク遂行 | Recon / Vulnerability Analysis / Exploit Agents | 偵察、脆弱性探索、Exploit などの個別タスクを進める |
| 3. 再現確認 | Verification Agent | 発見候補を再現確認し、偽陽性を落とす |
| 4. レポート作成 | Report Agent | 確認済みの脆弱性を報告可能な形にまとめる |
各ステップは共有状態を参照しながら進みます。
以下、特に重要な 2 つの設計判断を説明します。
なぜ multi-agent system にしたのか
弊社のペンテスト AI Agent は、単一の Agent ですべてを行う構成にはしていません。フェーズごとに専門化された Agent が協調する multi-agent system として構築しています。
Web ペンテストを全自動化する OSS には westonbrown/Cyber-AutoAgent のように single agent で構築されているものもあります。どちらが良いかは目的次第ですが、弊社は以下の点で multi-agent system のほうが有利と判断しました。
- フェーズごとのチューニングがしやすい: モデル、システムプロンプト、ツールセット、ガードレールをフェーズ単位で個別に最適化できる。偵察と Exploit では必要な能力もガードレールも大きく異なるため、この自由度は大きい。
- フェーズ特化の偽陽性チェッカーを差し込める: 機械的なフィルタを各フェーズに合わせて最適化できる。
- 状態管理を分離できる: フェーズによっては、独自のステート管理や忘却処理が欲しくなることがある。
代償として複数 Agent と共有状態を管理する複雑性は増えます。それでも、上記のメリットが上回ると判断しました。先行する XBOW も multi-agent system を採用しており、実用規模で成立し得る方向性だと考えています。
全自動で動かすためのガードレール
Human-in-the-Loop を介さない全自動化を選ぶ以上、人間の監督なしで安全に動作するためのガードレールは不可欠です。
弊社ではガードレールを 2 層で実装しています。
- プロンプトレベルのガードレール: 各 Agent のシステムプロンプトに、対象スコープや禁止行為を明示する。
- システムレベルのガードレール: 全トラフィックを中間者プロキシ (L7 Egress Gateway) に通し、スコープ外のホストへのリクエスト、過剰なリクエストレート、未知のプロトコルなどをプロキシ側で機械的に遮断する。
プロンプトレベルだけに頼ると、LLM が指示を無視または誤解した時点で安全性が崩れます。全自動運用には、LLM の挙動と独立した経路で制約をかけるシステムレベルのガードレールが必要です。MITM Proxy を通過したリクエスト / レスポンスは記録され、後段で自動的にスキャナによる検査に回されます。
既存ベンチマークだけでは足りなかったこと
multi-agent system の利点である フェーズごとのチューニング を継続的に回すには、フェーズ単位で性能差分を測れるベンチマークが必要です。
ペンテスト AI Agent の性能評価では、PortSwigger Academy Lab や XBOW Benchmark のようなベンチマークが使われます。これらは攻撃チェーン全体としての強さを測る評価として有用です。
一方で、弊社の改善ループでは以下の点が課題になりました。
- モデル性能の進化により、既存ベンチマークは上位帯でスコアが飽和しつつある
- Web Browser を使った初期偵察や Exploit の安全性検証など、細かなチューニング差分を測りにくい
- モデル切り替え時に、特定フェーズだけ性能が落ちるデグレを検知しにくい
そこで弊社では、フェーズごとの性能改善・コスト最適化に向けた独自ベンチマークを開発し、継続的な評価に利用しています。詳細は後日、別の記事で紹介する予定です。
さいごに
初回フィールドテストでは、実環境に対する一定の有用性を確認しました。今後はより高度な攻撃チェーンの自動化と、より広範な攻撃対象への対応を目指して研究開発を続けていきます。
弊社ではペンテスト AI Agent の実証実験にご協力いただける企業様を募集しています。ご興味のある方はぜひご連絡ください。