Tatsuya Abe
Tatsuya Abe 
Introduction
Since 2025/5, Layer8 has been working on R&D for a pentest AI agent that fully automates web application penetration testing. In 2026/1, we ran its first field test and confirmed that it can find vulnerabilities in real-world environments.
The technology we are developing is intended to validate vulnerabilities only in authorized environments and help service providers improve their defenses. It is not intended for abuse or for attacking third-party systems without permission.
Our pentest AI agent targets black-box and gray-box testing of web applications. The current inputs and execution scope are as follows.
| Item | Description |
|---|---|
| Input | Target URL. For gray-box testing, credentials are also provided. |
| Execution scope | Initial reconnaissance, vulnerability confirmation, report generation |
| Output | Vulnerability report |
| Out of scope | A bot that automatically submits vulnerability reports, a general-purpose internet crawler, white-box testing, network-level scanning |
This post covers the initial benchmark evaluation, the first field test results, and the main design decisions behind the system.
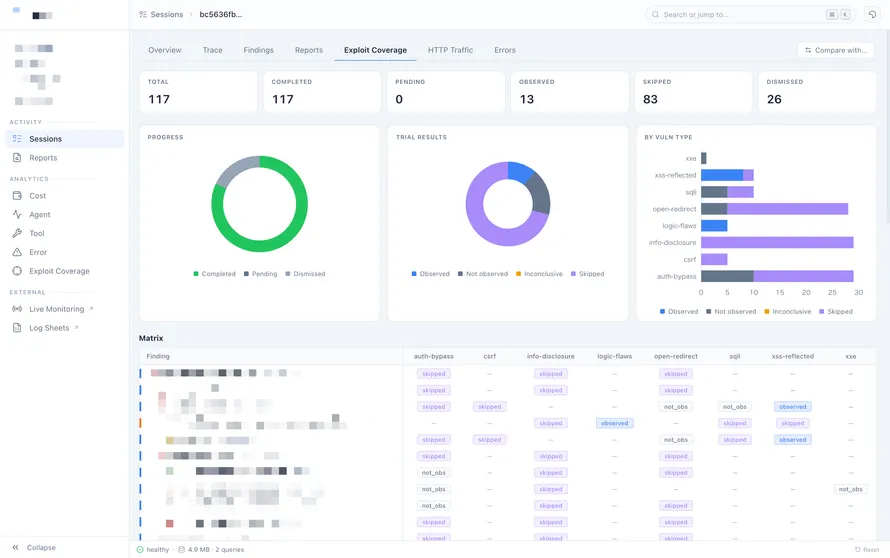
Baseline Evaluation on PortSwigger Academy Lab
PortSwigger Web Security Academy is a free web security training platform provided by PortSwigger, the company behind Burp Suite. It provides lab environments for common vulnerability classes such as SQLi, XSS, and SSRF, and is widely used as a yardstick for web pentest capability across both humans and AI agents.
In the early stage of development, we used PortSwigger Academy Lab to improve core behaviors such as exploration, exploitation, and verification. With a one-hour time limit per lab, the agent solved 84% of the labs as of 2025/12/2.
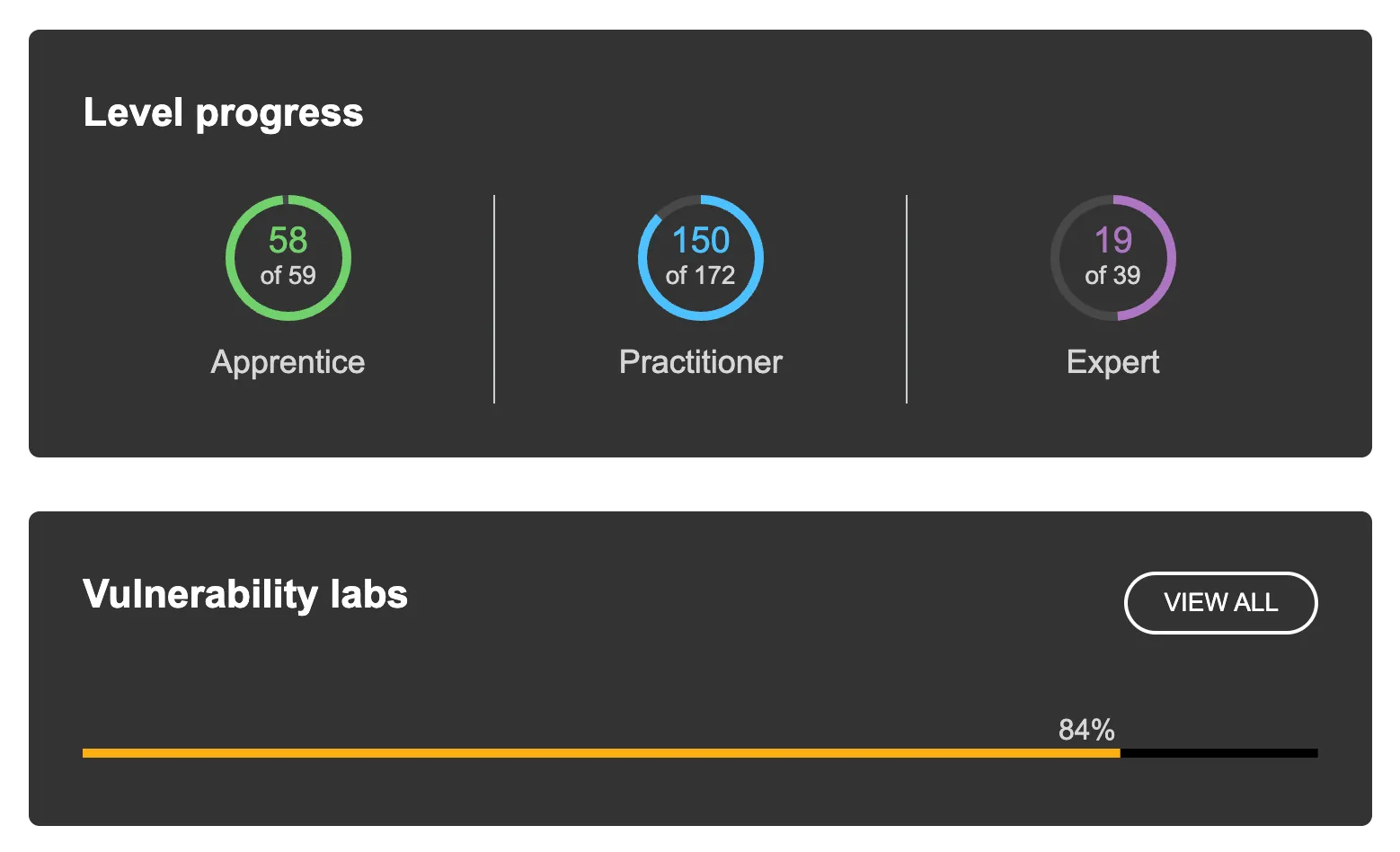
Based on this result, we decided it was time to test whether the agent could find vulnerabilities not only in known training environments, but also in real-world systems.
First Field Test Results
For the first field test, we evaluated the agent through two channels: public programs and a partner company’s staging environment.
| Channel | Target | Input | Purpose |
|---|---|---|---|
| HackerOne | Public VDP / BBP programs | URL only | Black-box validation against real systems |
| Pro bono PoC | Staging environment of one partner company | URL and credentials | Gray-box validation against a real system |
HackerOne
HackerOne is a bug bounty platform that aggregates vulnerability disclosure programs operated by companies and government agencies. Programs mainly fall into two categories.
- VDP (Vulnerability Disclosure Program): a responsible disclosure channel that generally does not pay bounties. Many government programs fall into this category.
- BBP (Bug Bounty Program): a commercial program that pays bounties for valid vulnerability reports.
We ran the agent against 30 target URLs across VDP and BBP programs. Each target was tested as a one-hour black-box test with only the URL as input.
| Category | Result |
|---|---|
| VDP | 3 vulnerability reports were triaged (= validated as legitimate vulnerabilities by the receiving organization) in the U.S. Department of Defense (DoD) program |
| VDP leaderboard | #86 worldwide in the 90-day category |
| BBP | 3 reports submitted, all marked as duplicates and not eligible for bounties |
Based on these results, we have wrapped up the HackerOne experiment for now and are focusing on tuning with our own benchmarks, described later.
Pro Bono PoC
We also ran a pro bono fully autonomous pentest against the staging environment of one partner company. With only a URL and credentials as input, the agent found multiple exploitable vulnerabilities, including a Stored XSS.
Details about the target system and the vulnerabilities are not disclosed due to confidentiality obligations and abuse prevention.
Architecture and Design Decisions
There were two main design challenges in running a pentest AI agent fully autonomously.
- How to handle the different requirements of reconnaissance, vulnerability analysis, exploitation, and verification
- How to prevent out-of-scope access and excessive request volume without human supervision
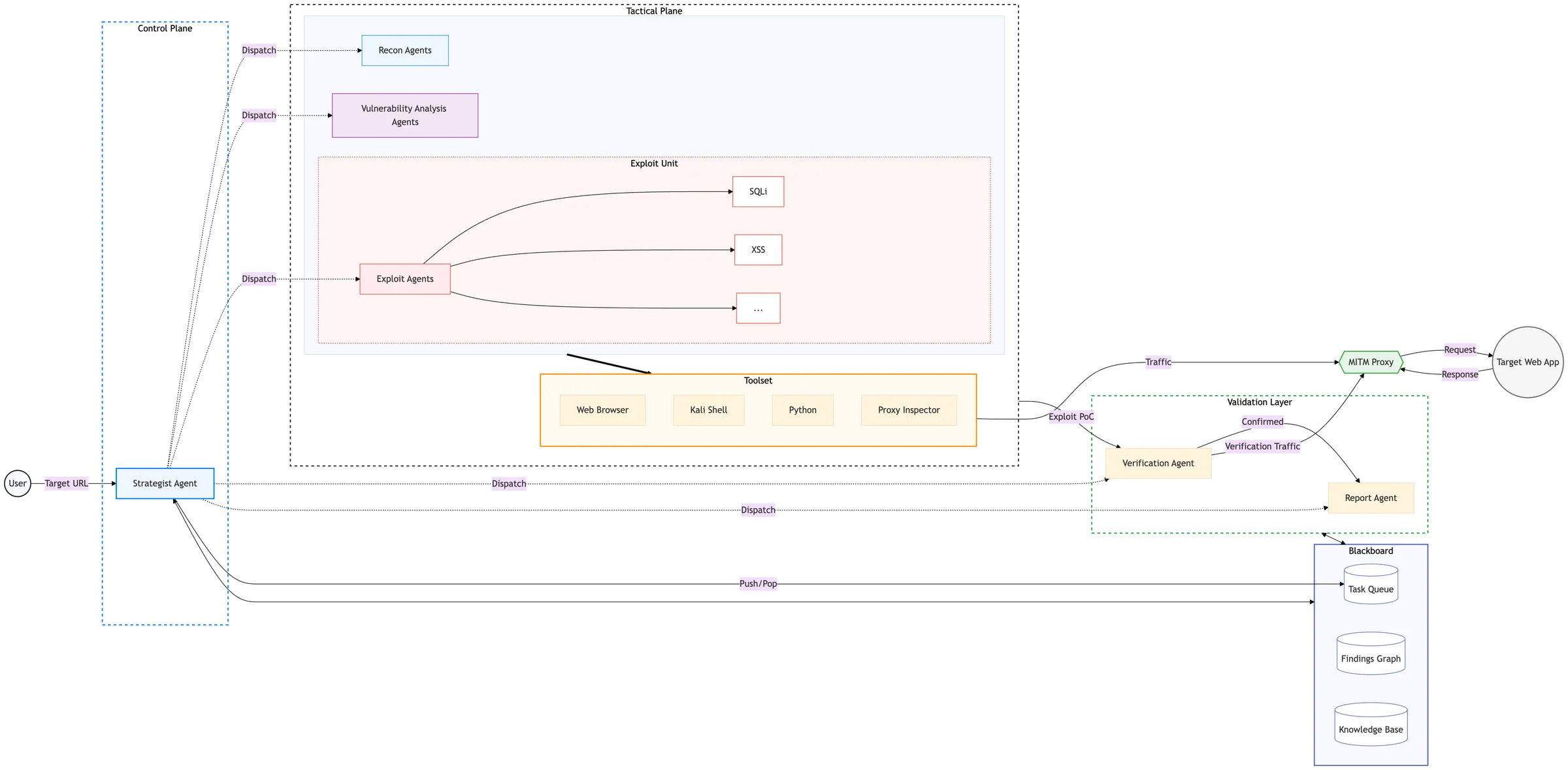
With those constraints in mind, the current architecture is shown below. We omit proprietary details and only cover what can be shared publicly.
---
config:
layout: dagre
theme: base
---
flowchart LR
%% Entry Point
U(("User")) -- Target URL --> SA
%% Control Plane
subgraph Control_Plane["Control Plane"]
SA["Strategist Agent"]
end
%% Core Components
subgraph Blackboard["Blackboard"]
direction LR
TQ[("Task Queue")]
FG[("Findings Graph")]
HT[("Knowledge Base")]
end
%% Tactical Plane
subgraph Tactical["Tactical Plane"]
direction LR
subgraph Agents[" "]
direction LR
R["Recon Agents"]
V["Vulnerability Analysis Agents"]
subgraph E_Unit["Exploit Unit"]
direction TB
E["Exploit Agents"]
E --> SQLI["SQLi"]
E --> XSS["XSS"]
E --> ETC["..."]
end
end
Agents ==> Toolset
subgraph Toolset["Toolset"]
direction TB
BW["Web Browser"]
SH["Kali Shell"]
PY["Python"]
PI["Proxy Inspector"]
end
end
%% Validation Layer
subgraph Validation["Validation Layer"]
direction TB
VA["Verification Agent"]
RA["Report Agent"]
end
%% Infrastructure
P_Svc{{"MITM Proxy"}}
TWA(("Target Web App"))
%% Logic Flow
SA <--> Blackboard
SA -. "Dispatch" .-> R & V & E & VA & RA
SA -- "Push/Pop" --> TQ
%% Output & Verification Flow
Tactical -- Exploit PoC --> VA
VA -- Confirmed --> RA
Validation <--> Blackboard
%% Traffic Flow
Toolset -- Traffic --> P_Svc
VA -- Verification Traffic --> P_Svc
P_Svc -- Request --> TWA
TWA -- Response --> P_Svc
%% Style Definitions
style U fill:#f8f9fa, stroke:#212529, stroke-width:2px
style SA fill:#eef6ff, stroke:#007bff, stroke-width:2px
style Control_Plane fill:#ffffff, stroke:#007bff, stroke-width:2px, stroke-dasharray: 5 5
style Blackboard fill:#f8f9ff, stroke:#5c6bc0, stroke-width:2px
style TQ fill:#ffffff, stroke:#5c6bc0, stroke-width:1px
style FG fill:#ffffff, stroke:#5c6bc0, stroke-width:1px
style HT fill:#ffffff, stroke:#5c6bc0, stroke-width:1px
style Tactical fill:#ffffff, stroke:#333333, stroke-width:2px, stroke-dasharray: 5 5
style R fill:#f0f7ff, stroke:#2196f3, stroke-width:1px
style V fill:#f3e5f5, stroke:#9c27b0, stroke-width:1px
style E_Unit fill:#fff5f5, stroke:#f44336, stroke-width:1px, stroke-dasharray: 2 2
style E fill:#ffebee, stroke:#f44336, stroke-width:1px
style SQLI fill:#ffffff, stroke:#f44336, stroke-width:1px
style XSS fill:#ffffff, stroke:#f44336, stroke-width:1px
style ETC fill:#ffffff, stroke:#f44336, stroke-width:1px
style Toolset fill:#fffaf0, stroke:#fb8c00, stroke-width:2px
style P_Svc fill:#e8f5e9, stroke:#4caf50, stroke-width:2px
style TWA fill:#f5f5f5, stroke:#757575, stroke-width:2px
style Validation fill:#ffffff, stroke:#28a745, stroke-width:2px, stroke-dasharray: 5 5In the diagram, Recon / Vulnerability Analysis / Exploit are not single agents. They represent groups of agents split by role. The high-level flow is as follows.
| Step | Main owner | Description |
|---|---|---|
| 1. Strategy planning | Strategist Agent | Looks at shared state and decides the next task to execute |
| 2. Task execution | Recon / Vulnerability Analysis / Exploit Agents | Performs individual tasks such as reconnaissance, vulnerability analysis, and exploitation |
| 3. Verification | Verification Agent | Reproduces candidate findings and filters out false positives |
| 4. Report generation | Report Agent | Turns confirmed vulnerabilities into a reportable form |
Each step proceeds while referring to shared state.
The two most important design decisions are described below.
Why We Chose a Multi-Agent System
Our pentest AI agent does not use a single agent to do everything. It is built as a multi-agent system, where agents specialized for different phases collaborate.
Some open-source projects for fully autonomous web pentesting, such as westonbrown/Cyber-AutoAgent, use a single-agent architecture. The right choice depends on the goal, but we chose a multi-agent system for the following reasons.
- Per-phase tuning is easier: models, system prompts, toolsets, and guardrails can be optimized independently for each phase. Reconnaissance and exploitation require different capabilities and different guardrails, so this flexibility matters.
- Phase-specific false-positive checkers can be added: mechanical filters can be optimized for each phase.
- State management can be separated: some phases benefit from their own state management or forgetting behavior.
The trade-off is that managing multiple agents and shared state adds complexity. Even so, we concluded that the benefits outweigh the cost. XBOW also uses a multi-agent system, which suggests that this direction can work at practical scale.
Guardrails for Fully Autonomous Execution
Because we chose full automation without a Human-in-the-Loop, guardrails are essential for safe operation without human supervision.
We implement guardrails in two layers.
- Prompt-level guardrails: each agent’s system prompt explicitly states the allowed scope and prohibited behaviors.
- System-level guardrails: all traffic passes through a man-in-the-middle proxy (L7 Egress Gateway), which mechanically blocks out-of-scope hosts, excessive request rates, unknown protocols, and similar cases.
If we rely only on prompt-level guardrails, safety breaks as soon as the LLM ignores or misunderstands an instruction. Full automation requires system-level guardrails that enforce constraints on a path independent of the LLM’s behavior. Requests and responses that pass through the MITM Proxy are also recorded and automatically sent to scanners in a later stage.
Why Existing Benchmarks Were Not Enough
To keep iterating on per-phase tuning, which is one of the advantages of a multi-agent system, we need benchmarks that can measure performance differences at the phase level.
For pentest AI agents, benchmarks such as PortSwigger Academy Lab and XBOW Benchmark are used for performance evaluation. They are useful for measuring end-to-end attack-chain strength.
At the same time, they did not fully match our improvement loop for the following reasons.
- As model capabilities improve, existing benchmarks are starting to saturate at the upper end.
- They make it hard to measure fine-grained tuning differences, such as initial reconnaissance with a Web Browser or safety checks for exploitation.
- They make it hard to detect regressions where only a specific phase gets worse after switching models.
For this reason, we developed our own benchmarks for phase-level performance improvement and cost optimization, and use them for continuous evaluation. We plan to share the details in a future post.
Closing
In the first field test, we confirmed a certain level of usefulness against real-world environments. We will continue R&D toward automating more advanced attack chains and supporting a broader range of targets.
We are looking for companies interested in participating in proof-of-concept testing of our pentest AI agent. If you are interested, please contact us.