Tatsuya Abe
Tatsuya Abe 
はじめに
ペンテスト AI Agent は、一度作って終わりのソフトウェアではありません。実行ログから失敗やコストの偏りを見つけ、次の改善に反映し続けることで性能が上がっていきます。
弊社では、テレメトリ基盤を単なるデバッグ用途ではなく、ペンテスト AI Agent の改善速度を決めるプロダクト基盤として扱っています。
この 1 年でログ分析の手段は LLMOps SaaS から Google Sheets へ、さらに独自のテレメトリ基盤へ移りました。
本記事では、その移行の理由と、最終的に採用した以下の設計について紹介します。
- 人間には、ドメイン特化のモニタリングダッシュボードを提供する
- Coding AI Agent には、raw SQL access を渡す
なぜテレメトリ基盤が必要だったのか
ペンテストは実行内容が複雑になりがちで、職人技的な要素も強い領域です。目指すべきワークフロー自体を試行錯誤しながら作る必要があり、ログ分析への要求もその過程で変わっていきます。
弊社のペンテスト AI Agent は以下の特徴を持ちます。
- 長尺: 1 session = 数時間の連続実行
- multi-agent: 複数の agent が、それぞれ複数の tool を呼び出しながら、協調してタスクを進める
- 試行錯誤型: 直前の事実から次のアクションを動的に決定する
- 高コスト: 高性能なモデルを頻繁に呼び出すため、コストがかさむ
調整すべき点が多いため、1 session を詳しく追えるだけでは足りません。以下のような問いに継続的に答えられる必要があります。
- セッション横断で、どの phase / agent / tool がボトルネックになっているか
- どの種類の finding が、どの試行パターンから見つかっているか
- コストや token 使用量の偏りはどこで発生しているか
- 分析結果を、次の実装改善にどう接続するか
この要求に対して、最初から独自基盤を作るのが正解だったわけではありません。弊社ではプロダクトの成熟度に合わせて、LLMOps SaaS、Google Sheets、独自基盤の順にログ分析の手段を変えてきました。
LLMOps SaaS から始めた理由
前提として、これから AI Agent を作る場合は LLMOps SaaS から始めるのが良い と思います。開発初期は AI Agent 自体の設計も流動的で、テレメトリ基盤にあまりリソースを割きたくないためです。
弊社の場合は、今後大きな変更が減る見通しが立ってから独自基盤の構築に踏み切りました。ここに至るまで、半年以上かけて段階的にプロダクトを成熟させてきました。
LLMOps SaaS は、個々の session を追う用途では有効です。
一方で弊社のペンテスト AI Agent では、セッション横断の統計、独自ツール専用の表やグラフ、コストのボトルネック分析が必要です。これらを満たすには、汎用的な LLMOps SaaS だけでは厳しいと判断しました。
Google Sheets で見えた限界
特に強かったのが、各種ログを俯瞰したいというニーズです。そこで次に試したのが Google Sheets でした。検討理由は以下の通りです。
- 独自基盤の作り込みに工数を割かずに済む
- 複数種類のログを表形式で俯瞰できる
- マクロや Gemini を駆使すれば、ある程度の分析もシート上で完結させられる
- スキーマが緩く、ペンテスト AI Agent の破壊的変更を気軽に試せる
意外にも Google Sheets は想像以上に機能し、チューニングに大きく貢献しました (この間は LLMOps SaaS と併用せず、Google Sheets 一本で分析していました)。特に tool call の生ログを俯瞰できる点が強力で、全体の傾向や課題をすばやく把握できます。
一方で、深く調査しようとすると手動フィルタや複数シートの行き来が増え、分析のたびに同じ手間が発生するようになりました。情報は出せるが、そこにたどり着くまでが大変 という課題が見えてきたのです。この時点でペンテスト AI Agent の構成はある程度固まっており、細かなチューニングに向けて独自基盤を作り込む段階に入ったと判断しました。
独自基盤で改善ループを作る
これに踏み切った時点で、ペンテスト AI Agent 本体の破壊的変更は減る見通しが立っていました。それでも 変更はゼロにならない ため、変更耐性をアーキテクチャレベルで担保する必要があります。現在運用している独自基盤は、この前提で設計しています。重要なのは、生ログを柔軟に溜めること、読み手ごとに最適なインターフェースを分けること、分析結果を改善ループへ接続できる形にすることです。
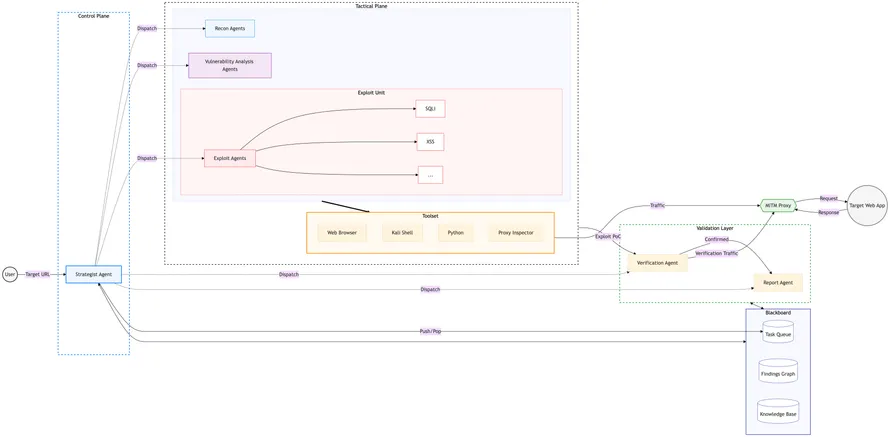
アーキテクチャ全体像
---
config:
layout: dagre
theme: base
---
flowchart LR
%% Producer
subgraph Producer["Producer"]
AG["Pentest AI Agent"]
end
%% BigQuery
subgraph BQStorage["BigQuery"]
direction TB
LAKE[("Data Lake")]
MV[("Materialized Views<br/>(read-optimized)")]
LAKE --> MV
end
%% Consumers
subgraph Consumers["Consumers"]
direction TB
UI["Monitoring Dashboard"]
SQL["Raw SQL Access"]
end
H(("Human"))
AGT(("Coding AI Agent"))
PR{{"改善提案"}}
AG -- log --> LAKE
MV --> UI
MV --> SQL
LAKE --> SQL
UI -. read .-> H
SQL -. read .-> AGT
AGT --> PR
PR -. feedback .-> AG
%% Style
style AG fill: #eef6ff, stroke: #007bff, stroke-width: 2px
style Producer fill: #ffffff, stroke: #007bff, stroke-width: 2px, stroke-dasharray: 5 5
style BQStorage fill: #f8f9ff, stroke: #5c6bc0, stroke-width: 2px
style LAKE fill: #ffffff, stroke: #5c6bc0, stroke-width: 1px
style MV fill: #ffffff, stroke: #5c6bc0, stroke-width: 1px
style Consumers fill: #fffaf0, stroke: #fb8c00, stroke-width: 2px
style UI fill: #ffffff, stroke: #fb8c00, stroke-width: 1px
style SQL fill: #ffffff, stroke: #fb8c00, stroke-width: 1px
style H fill: #f8f9fa, stroke: #212529, stroke-width: 2px
style AGT fill: #f8f9fa, stroke: #212529, stroke-width: 2px
style PR fill: #e8f5e9, stroke: #4caf50, stroke-width: 2px構成要素は大きく 3 つです。Producer はペンテスト AI Agent で、実行のたびに発生するログ (LLM call、tool call、finding 検出など) を書き出します。BigQuery は生ログを溜める Data Lake と、読み手向けに整形した Materialized Views (以降 MV) の 2 層構成です。Consumers は人間 (モニタリングダッシュボード経由) と Coding AI Agent (raw SQL access 経由) の 2 系統で、後者が改善ループを形成します。
以下、設計判断を順に見ていきます。
Schema 設計: 半構造化ログと MV
base table は固定カラムと JSON payload だけを持つ、シンプルな append-only log です。
CREATE TABLE pentest_events (
timestamp TIMESTAMP,
session_id STRING,
event_type STRING,
payload JSON, -- semi-structured payload
...
)
PARTITION BY DAY(timestamp)
CLUSTER BY (session_id, event_type);payload にはログ種別ごとに異なる構造体が入ります。例えば LLM call なら token 数、model 名、cache hit などです。tool call なら tool 名や引数、finding なら脆弱性情報、といった具合です。
payload のスキーマを緩く保っているのは、ペンテスト AI Agent 側の出力が今後も変わり続けると見込んでいるためです。新しいフィールドが増えたり、既存の名前が変わったりすることは避けられません。base table のスキーマを強く縛ると、ペンテスト AI Agent 側の変更にテレメトリ基盤が引きずられます。Google Sheets 運用で実感したのは、書き手側 (ペンテスト AI Agent) の自由度を奪わないこと の重要性です。これを今回の設計にも持ち込んでいます。
その代わり、読み手側の最適化とスキーマ差分の吸収は MV が担当します。
-- 例: LLM call の MV (一部抜粋)
CREATE MATERIALIZED VIEW pentest.mv_llm_calls AS
SELECT
session_id,
timestamp AS event_at,
JSON_VALUE(payload, '$.agent_name') AS agent_name,
JSON_VALUE(payload, '$.model') AS model,
CAST(JSON_VALUE(payload, '$.input_tokens') AS INT64) AS input_tokens,
CAST(JSON_VALUE(payload, '$.output_tokens') AS INT64) AS output_tokens,
CAST(JSON_VALUE(payload, '$.cached_input_tokens') AS INT64) AS cached_input_tokens,
CAST(JSON_VALUE(payload, '$.thoughts_tokens') AS INT64) AS thoughts_tokens,
CAST(JSON_VALUE(payload, '$.tool_use_prompt_tokens') AS INT64) AS tool_use_prompt_tokens
FROM `pentest.pentest_events`
WHERE event_type = 'llm_response';この設計には 2 つの利点があります。
- JSON 抽出後は軽量な scalar 列だけになり、consumer 側のクエリスキャン量が激減する
- スキーマ差分 (新フィールドの追加、旧フィールドの廃止など) を MV 定義側で吸収し、ペンテスト AI Agent 本体が過去のログ schema との互換性に縛られずに済む
書き手側 (ペンテスト AI Agent) には Data Lake の柔軟性を、読み手側 (UI / 分析) には scalar 列の高速性を提供する。この両立が狙いです。
インターフェース設計: 人間向け UI と Coding AI Agent 向け raw SQL
読み手は人間と Coding AI Agent の 2 系統ですが、同じインターフェースを渡す必要はありません。人間には固定クエリ UI、Coding AI Agent には raw SQL access を渡す構成にしています。
一方で、MCP tool として事前定義クエリを配る案は採用していません。共通クエリを用意すれば、人間からも Coding AI Agent からも同じ問いを投げられますが、Coding AI Agent 側の問いの自由度が下がるためです。
---
config:
layout: dagre
theme: base
---
flowchart TB
BQ[(BigQuery)] --> RA["Read Layer"]
RA --> UI["Monitoring Dashboard<br/>固定クエリ + drill-down"]
RA --> SQL["Raw SQL Access<br/>(BigQuery API)"]
UI --> H(("Human<br/>定常監視"))
SQL --> AG(("Coding AI Agent<br/>改善提案 / トラブルシューティング"))
DROP["MCP tool<br/>事前定義クエリ"]:::dropped
classDef dropped stroke-dasharray: 5 5, stroke: #999, color: #999, fill: #f5f5f5
style BQ fill: #f8f9ff, stroke: #5c6bc0, stroke-width: 2px
style RA fill: #ffffff, stroke: #5c6bc0, stroke-width: 1px
style UI fill: #fffaf0, stroke: #fb8c00, stroke-width: 2px
style SQL fill: #fffaf0, stroke: #fb8c00, stroke-width: 2px
style H fill: #f8f9fa, stroke: #212529, stroke-width: 2px
style AG fill: #eef6ff, stroke: #007bff, stroke-width: 2pxconsumer ごとの用途とインターフェースは以下の通りです。
| consumer | 主な用途 | 最適インターフェース |
|---|---|---|
| 人間 | 定常監視 + 想定済みドリルダウン | 固定クエリ + UI コンポーネント |
| Coding AI Agent | 改善提案 / トラブルシューティング | 任意 SQL を書ける raw access |
この非対称な設計により、人間には定常監視しやすい画面を提供しつつ、Coding AI Agent には毎回違う問いを立てられる余地を残しています。
モニタリングダッシュボード設計
モニタリングダッシュボードは「何でも見られる汎用ダッシュボード」を目指していません。ペンテストのワークフローに沿った opinionated な画面構成にしています。
なお、実際に収集しているテレメトリデータやモニタリングダッシュボードの詳細な画面構成は、ペンテスト AI Agent の内部設計や評価観点に関わるため非公開とします。
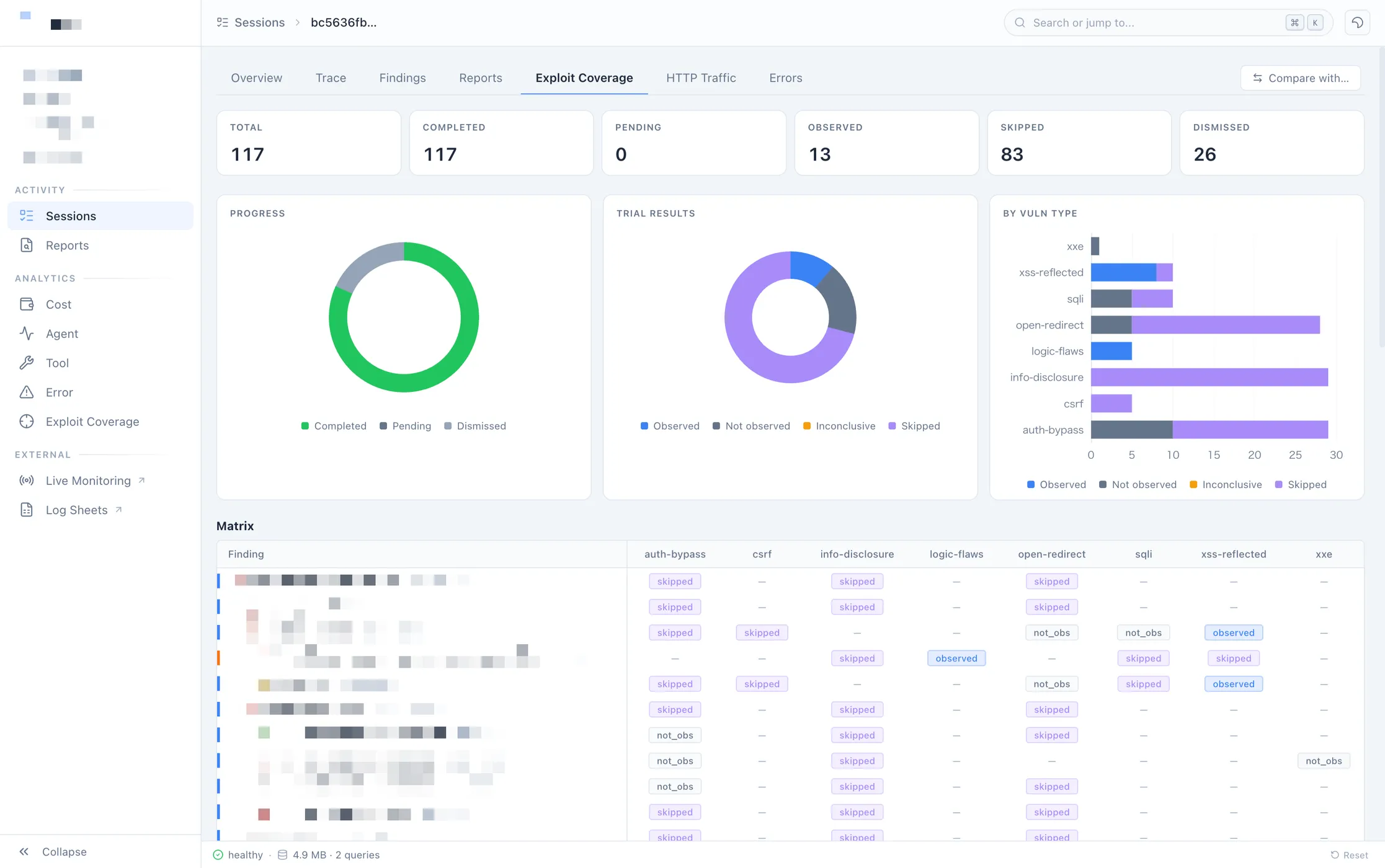
以下は、現在運用しているモニタリングダッシュボードの一例です。
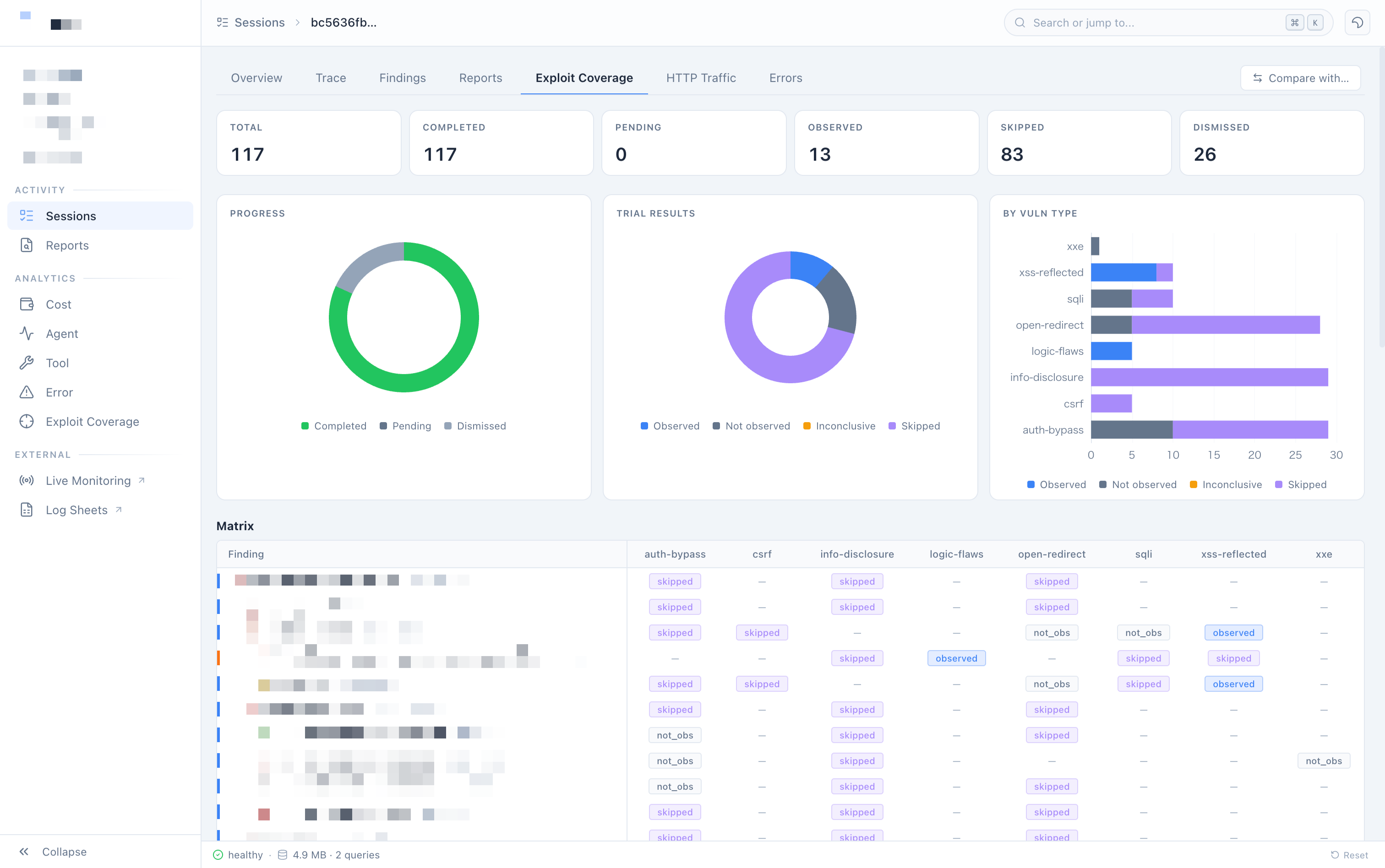
Coding AI Agent によるテレメトリ分析
ここまでの非対称な設計で特に効いているのが、Coding AI Agent がペンテスト AI Agent のテレメトリを読み、改善ループを回せる点です。これは単なる分析自動化ではありません。ペンテスト AI Agent を継続的に改善するための開発フローそのものです。
弊社では Coding AI Agent 向けに分析用 Agent Skills を整備しています。例えばコスト分析の Skill では、以下の流れを 1 session で完結させます。
- SQL でテレメトリを直接分析する
- agent / model / tool ごとのコストや token 使用量の傾向を集計する
- コストや token 使用量が突出した session を特定し、tool result の中身まで深掘りする
- ボトルネックを特定し、ペンテスト AI Agent への改善提案を出す
Agent Skills には「どのテーブルに何が入っているか」「どういう SQL を書くべきか」「分析 → 仮説 → 対策のマッピング」が記載されており、Coding AI Agent は必要な Skill を読み込みながら自走します。
---
config:
layout: dagre
theme: base
---
flowchart LR
AG["ペンテスト AI Agent 実行"] -- telemetry --> BQ[(BigQuery)]
BQ -- "Agent Skills" --> INV["Coding AI Agent が<br/>SQL で仮説検証"]
INV --> HYP["ボトルネック特定"]
HYP --> PR{{"改善提案"}}
PR -. feedback .-> AG
style AG fill: #eef6ff, stroke: #007bff, stroke-width: 2px
style BQ fill: #f8f9ff, stroke: #5c6bc0, stroke-width: 2px
style INV fill: #ffffff, stroke: #fb8c00, stroke-width: 2px
style HYP fill: #fff5f5, stroke: #f44336, stroke-width: 2px
style PR fill: #e8f5e9, stroke: #4caf50, stroke-width: 2pxこのループには、以下の 3 つが必要です。
- Coding AI Agent が任意の SQL を書けること (= MCP tool で問いを縛らない)
- スキーマが安定して読めること (= MV による差分吸収)
- ドメイン知識が Agent Skills として明文化されていること (= 汎用ではなくドメイン特化)
これらは、ここまで紹介してきた 3 つの設計判断に対応しています。このループは実際に回っており、少人数のチームでも改善サイクルを維持しやすくなりました。
さいごに
弊社のペンテスト AI Agent では、ログ分析の手段を LLMOps SaaS から Google Sheets、そして独自基盤へ移してきました。最初から独自基盤を作るべきだった、という話ではありません。各フェーズで「いまプロダクトに必要な分析能力は何か」「どこまで作り込むコストを払うか」を判断し直してきた結果です。
今回独自基盤に踏み切れたもう一つの理由は、Coding AI Agent の進化です。独自ツールの開発・運用コストが大きく下がり、かつては重い意思決定だった「独自基盤の構築」のハードルも下がっています。開発・運用コストを織り込んでも、分析やチューニングのスピードは切り替え前より明らかに向上しています。
LLMOps SaaS が悪いというわけではありません。ただ、AI Agent を汎用的に抽象化したツールである以上、ペンテストのような特定ドメインのワークフローに特化したモニタリング体験までは提供しきれなかった、というだけです。
ペンテスト AI Agent の性能を上げ続けるには、実行ログを人間が眺めるだけでは足りません。人間向けには見るべき画面を絞り込み、Coding AI Agent には自由に問いを立てられる raw access を渡す。その結果を次の実装改善につなげるところまで含めて、改善ループとして設計する必要があります。今回紹介したテレメトリ基盤は、そのための設計例です。